Transformer
一、Transformer
传统 RNN 处理序列时需 “逐元素迭代”(如从文本第一个词算到最后一个),不仅效率低,还难以捕捉长距离语义关联(如 “猫” 和隔 10 个词的 “抓老鼠”)。Transformer 用自注意力机制打破这一限制,同时通过 “并行计算” 大幅提升训练效率,其核心设计可拆解为 “整体结构” 和 “关键组件” 两部分:
环境准备
pip install torch torchtext导入依赖
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import Multi30k
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
import math
import random1. 整体结构:编码器(Encoder)+ 解码器(Decoder)
Transformer 本质是 “编码器 - 解码器架构”,但不同任务可灵活选择使用部分结构(如文本理解用编码器,文本生成用解码器): 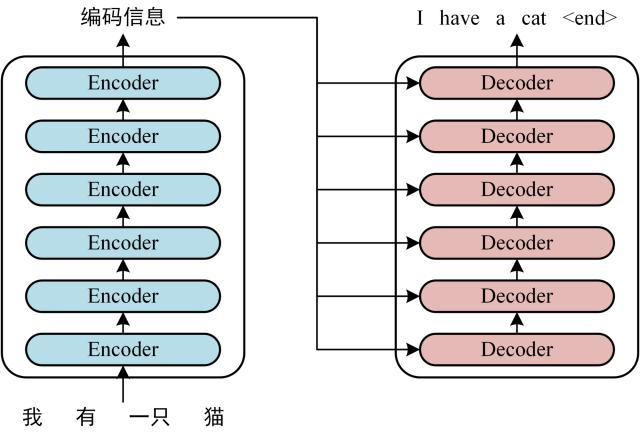 可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
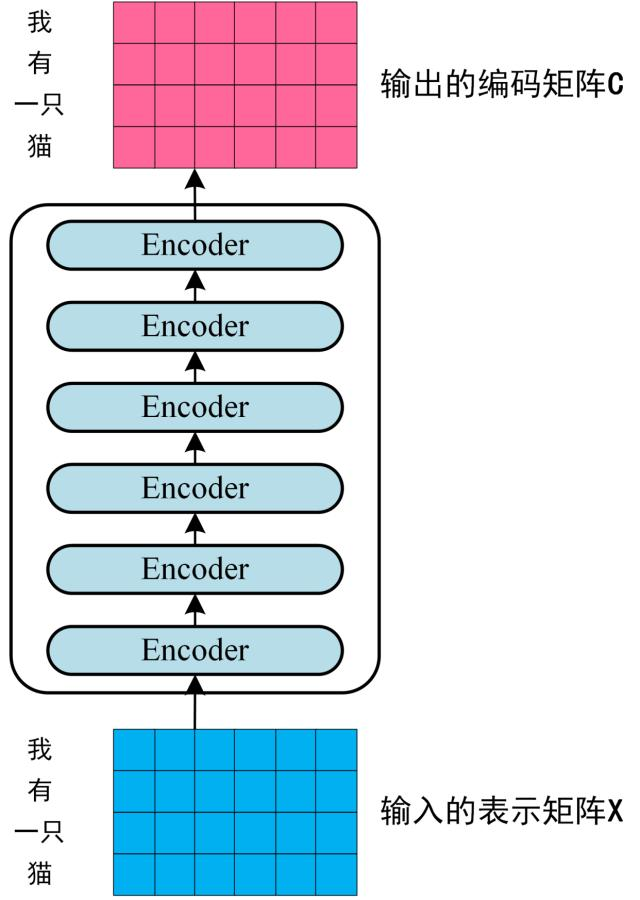
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
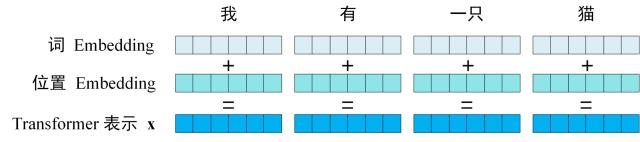
第一步:获取输入句子的每一个单词的表示向量 X、,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。 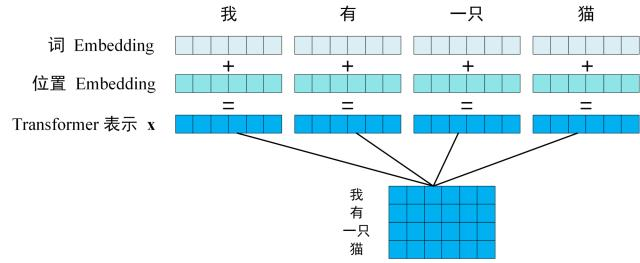
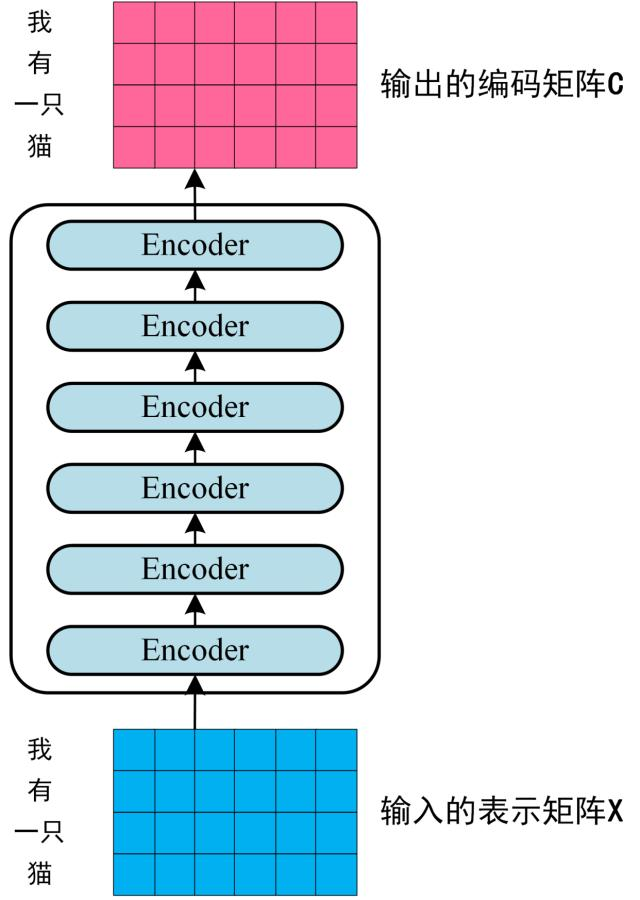
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
多个编码器的效果 : 提高模型泛化能力
- 参数学习:堆叠多个 Encoder block 增加了模型的参数数量,更多的参数意味着模型有更强的拟合能力,可以学习到更多不同类型的模式和特征。在大规模数据集上训练时,这些额外的参数可以让模型更好地捕捉数据的分布规律,减少过拟合风险,进而提高模型在不同任务和数据集上的泛化能力。
- 正则化效果:在一定程度上,堆叠多个 Encoder block 也起到了类似正则化的效果。 随着层数的增加,模型对输入数据的微小变化更加鲁棒,使得模型在面对新的、未见过的数据时,也能有较好的表现。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
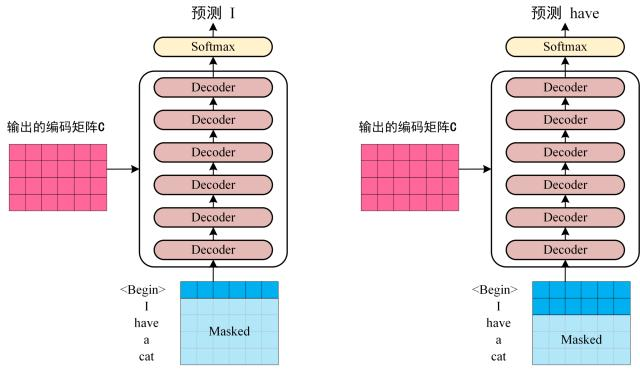
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "< Begin >",预测第一个单词 "I";然后输入翻译开始符 "< Begin >" 和单词 "I",预测单词 "have",以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
2. Transformer 的输入
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
2.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
self.embedding = nn.Embedding(vocabulary, dim)功能解释:
作用:将离散的整数索引(单词ID)转换为连续的向量表示
输入:形状为
[sequence_length]的整数张量输出:形状为
[sequence_length, dim]的浮点数张量(,n是序列长度,d是特征维度)
参数详解:
| 参数 | 含义 | 示例值 | 说明 |
|---|---|---|---|
vocabulary | 词汇表大小 | 10000 | 表示模型能处理的不同单词/符号总数 |
dim | 嵌入维度 | 512 | 每个单词被表示成的向量长度 |
工作原理:
创建一个可学习的嵌入矩阵[vocabulary, dim],例如当
vocabulary=10000,dim=512时,是一个10000×512的矩阵;每个整数索引对应矩阵中的一行:
# 假设单词"apple"的ID=42
apple_vector = embedding_matrix[42] # 形状 [512]在Transformer中的具体作用:
# 输入:src = torch.randint(0, 10000, (2, 10))
# 形状:[batch_size=2, seq_len=10]
src_embedded = self.embedding(src)
# 输出形状变为:[2, 10, 512]
# 每个整数单词ID被替换为512维的向量可视化表现:
原始输入 (单词ID):
[ [ 25, 198, 3000, ... ], # 句子1
[ 1, 42, 999, ... ] ] # 句子2
经过嵌入层后 (向量表示):
[ [ [0.2, -0.5, ..., 1.3], # ID=25的向量
[0.8, 0.1, ..., -0.9], # ID=198的向量
... ],
[ [0.9, -0.2, ..., 0.4], # ID=1的向量
[0.3, 0.7, ..., -1.2], # ID=42的向量
... ] ]为什么需要词嵌入:
语义表示:相似的单词会有相似的向量表示
降维:将离散的ID映射到连续空间(one-hot编码需要10000维 → 嵌入只需512维)
可学习:在训练过程中,这些向量会不断调整以更好地表示语义关系
2.2 位置 Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。**因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。**所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。 特点:
- 波长几何级数:覆盖不同频率
- 相对位置可学习:位置偏移的线性变换
可表示为 的线性函数 - 泛化性强:可处理比训练时更长的序列
- 对称性:sin/cos 组合允许模型学习相对位置
将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
代码实现:
class PositionalEncoding(nn.Module):
# Sine-cosine positional coding
def __init__(self, emb_dim, max_len, freq=10000.0):
super(PositionalEncoding, self).__init__()
assert emb_dim > 0 and max_len > 0, 'emb_dim and max_len must be positive'
self.emb_dim = emb_dim
self.max_len = max_len
self.pe = torch.zeros(max_len, emb_dim)
pos = torch.arange(0, max_len).unsqueeze(1)
# pos: [max_len, 1]
div = torch.pow(freq, torch.arange(0, emb_dim, 2) / emb_dim)
# div: [ceil(emb_dim / 2)]
self.pe[:, 0::2] = torch.sin(pos / div)
# torch.sin(pos / div): [max_len, ceil(emb_dim / 2)]
self.pe[:, 1::2] = torch.cos(pos / (div if emb_dim % 2 == 0 else div[:-1]))
# torch.cos(pos / div): [max_len, floor(emb_dim / 2)]
def forward(self, x, len=None):
if len is None:
len = x.size(-2)
return x + self.pe[:len, :]3. Self-Attention(自注意力机制)
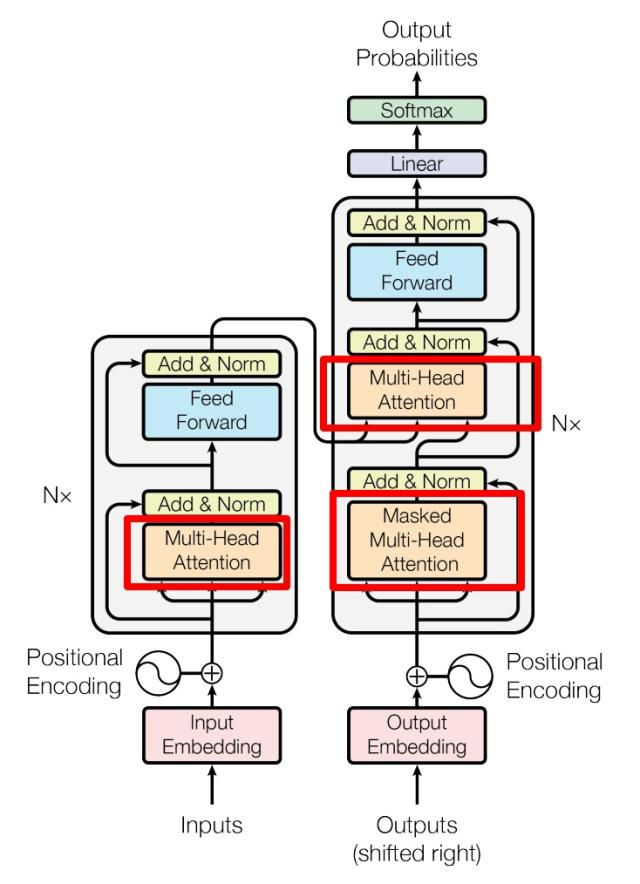
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
因为 Self-Attention是 Transformer 的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention,首先详细了解一下 Self-Attention 的内部逻辑。
3.1 Self-Attention 结构
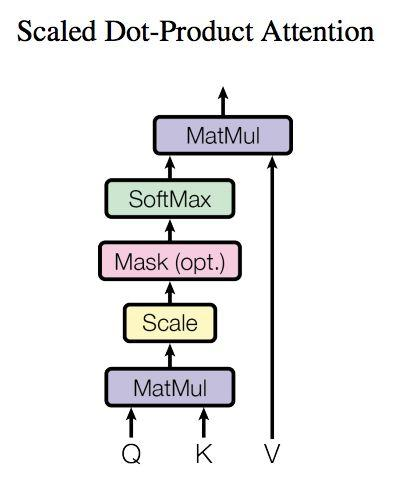
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵
3.2 Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵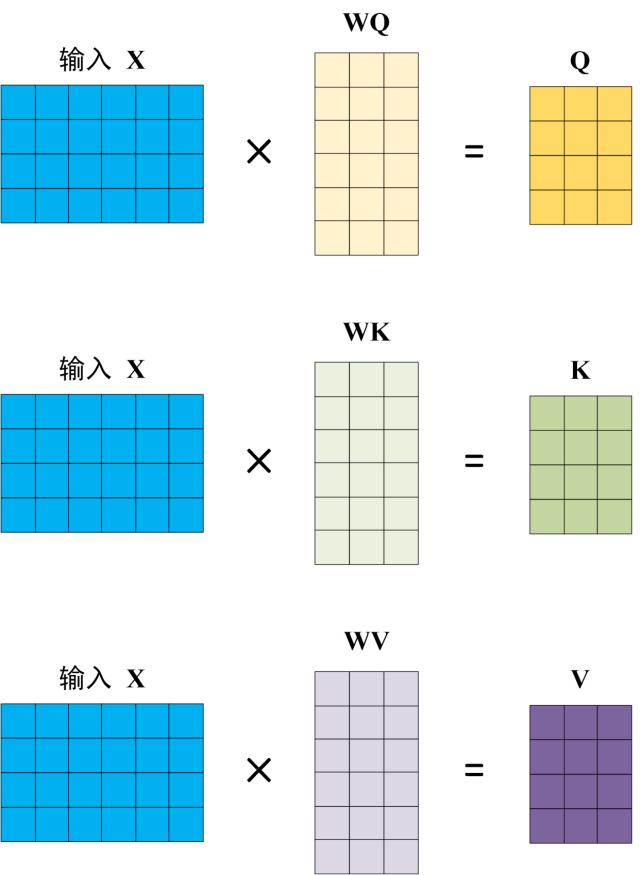
3.3 Self-Attention 的输出
得到矩阵
公式含义通俗解释
(Query,查询):可以理解为 “我现在要找什么信息”,比如你在搜索时输入的关键词对应的向量表示。 (Key,键):相当于 “各个信息条目本身的标识”,就像数据库里每条数据的索引键对应的向量。 (Value,值):是 “各个信息条目实际包含的内容”,即数据库里每条索引键对应的具体数据向量。 :计算 和 的相似度,得到每个 “查询” 与各个 “键” 的匹配程度分数。 :是缩放因子, 是 向量的维度。除以它是为了缓解内积计算后数值过大,导致 梯度消失的问题,让注意力分布更平稳。 :把相似度分数转化为 0 到 1 之间的权重,权重总和为 1,代表每个 “键 - 值” 对在当前 “查询” 下的重要程度。 - 最后乘以V:用得到的权重对 “值” 进行加权求和,得到最终的注意力输出,也就是结合了不同 “键 - 值” 对重要性的信息聚合结果。
公式中计算矩阵 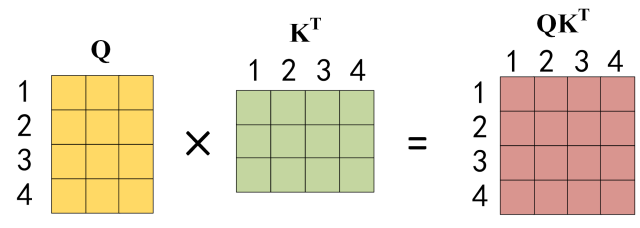
得到
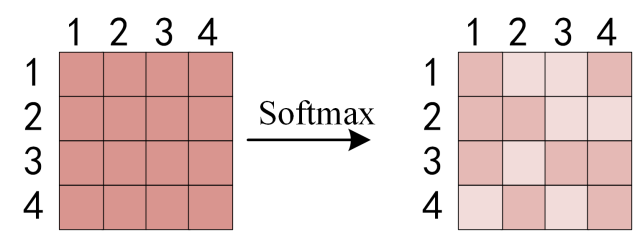
得到 Softmax 矩阵之后可以和
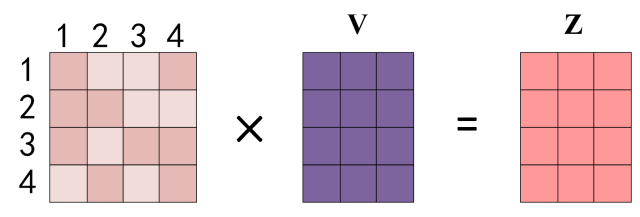
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出
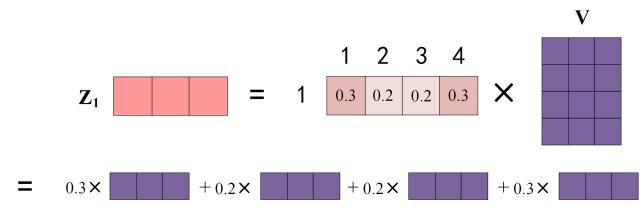
3.4 Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵
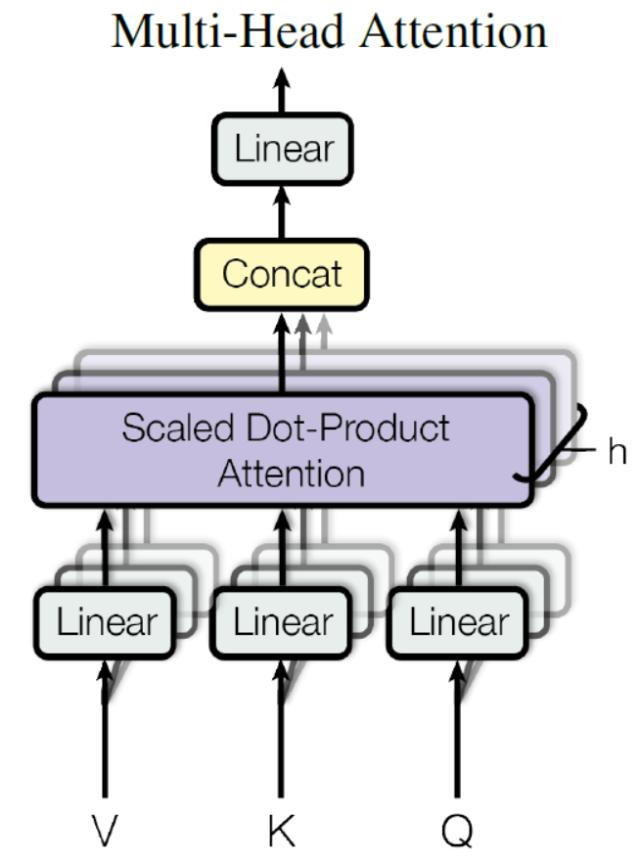
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入
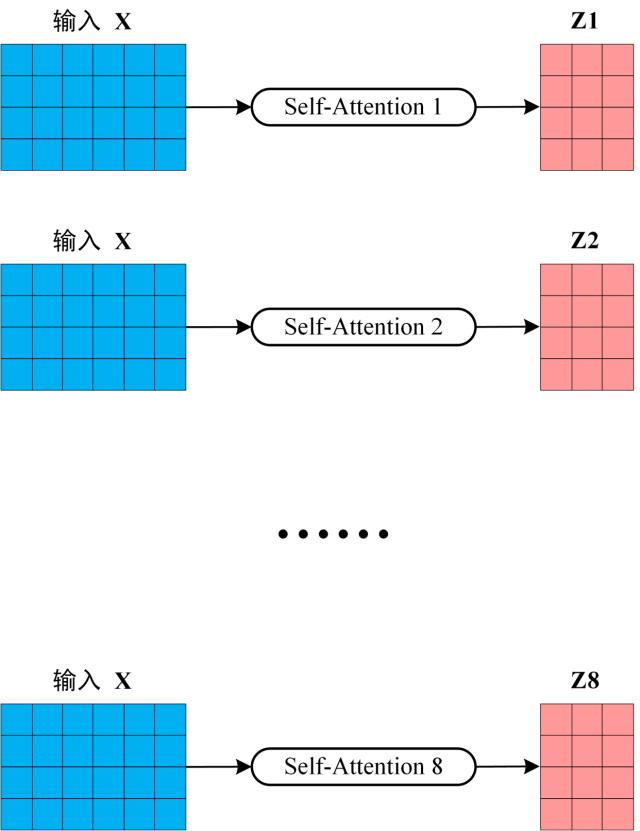
得到 8 个输出矩阵
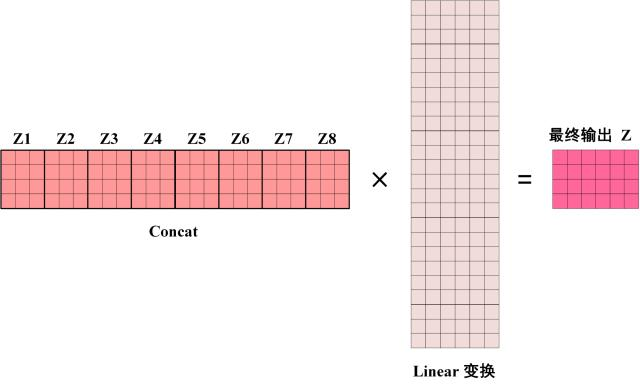
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
4. Encoder 结构
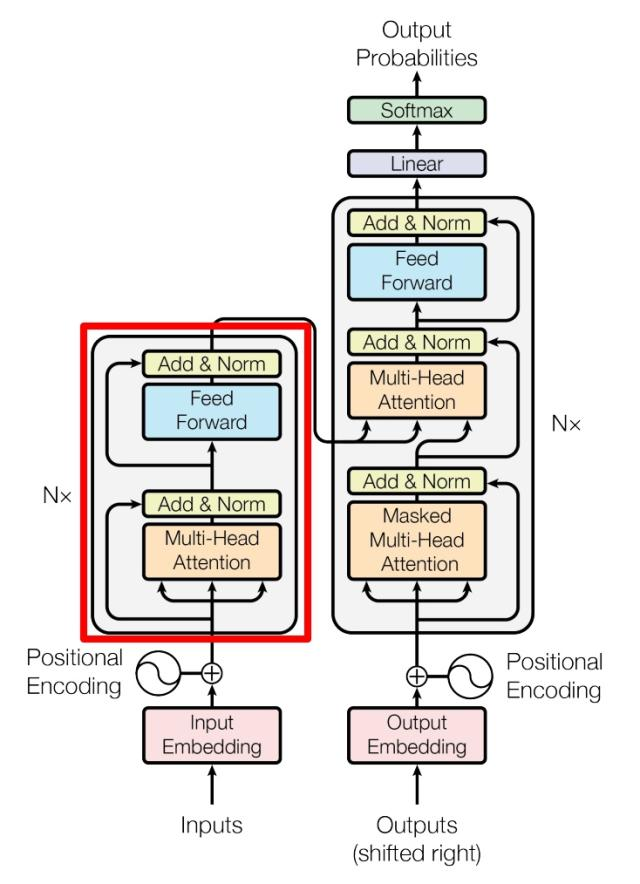
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
4.1 Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛
4.2 Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。
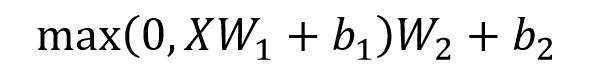
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
4.3 组成 Encoder
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 ,并输出一个矩阵 。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
5. Decoder 结构
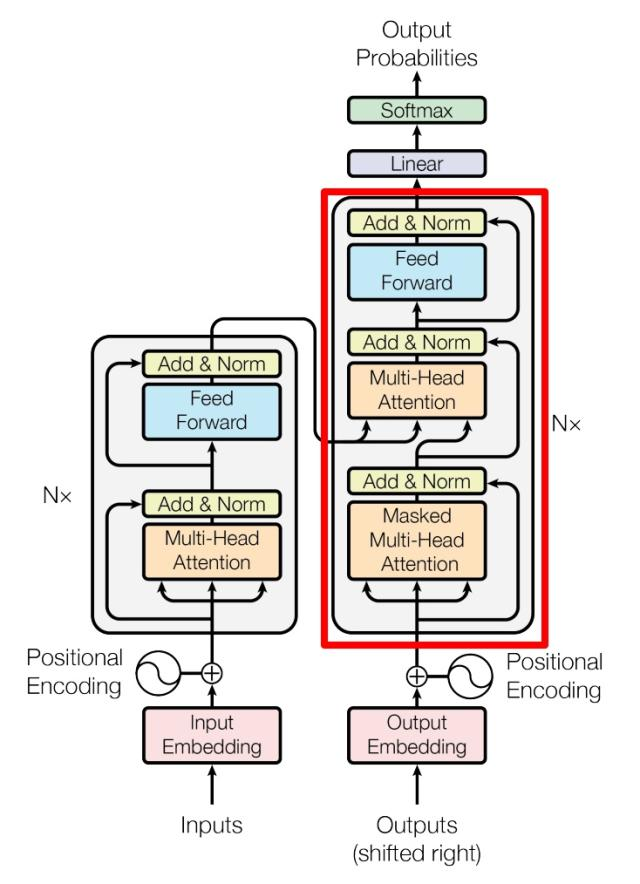
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
5.1 第一个 Multi-Head Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 "我有一只猫" 翻译成 "I have a cat" 为例,了解一下 Masked 操作。
下面的描述中使用了类似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的同学可以参考以下上一篇文章Seq2Seq 模型详解。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 "< Begin >" 预测出第一个单词为 "I",然后根据输入 "< Begin > I" 预测下一个单词 "have"。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 (< Begin > I have a cat) 和对应输出 (I have a cat < end >) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 "< Begin > I have a cat < end >"。
第一步: Decoder 的输入矩阵得到了一个5×5的 矩阵,将其遮盖变成Mask
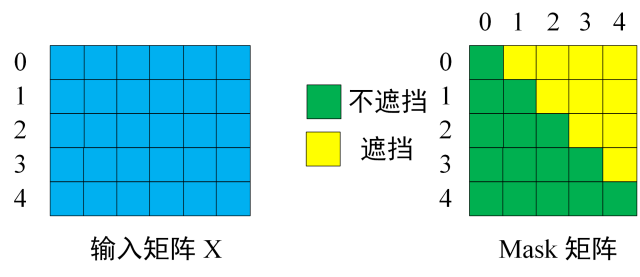
得到 Mask
第四步:使用 Mask
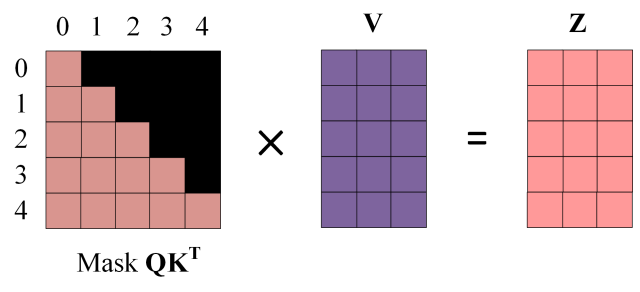
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵
5.2 第二个 Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
5.3 Softmax 预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
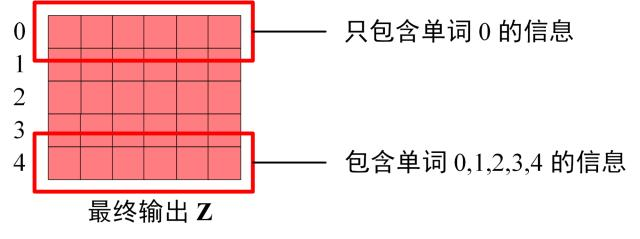
Softmax 根据输出矩阵的每一行预测下一个单词:
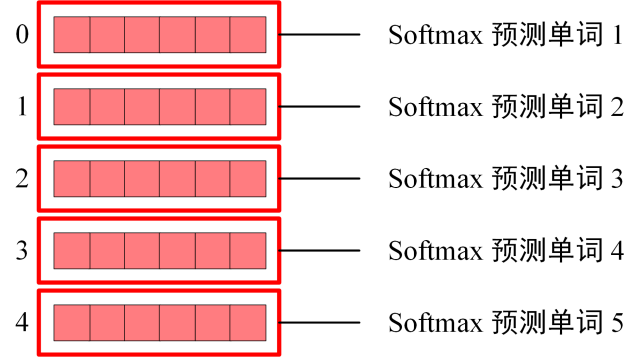
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
6. Transformer 总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。