CLIP Text Encode(prompt) - CLIP文本编码器
A. 概述
SD使用的是OpenAi的CLIP预训练模型,即别人训练好的拿来就用。
我们需要给出提示词Prompt, 然后利用CLIP模型将文本转换成嵌入表示Context,作为UNet的一个输入。
CLIP的作用,就是将文本转换为语言信息并使其与图像信息在UNet中采用Attention更好的偶合到一起,成为了文本和图像之间的连接通道。
CLIP的训练 用到了Text-Image配对的数据集,大概4亿张,主要是通过网络爬取图片以及相应的标签。如下图所示: 
B. 整体结构
CLIP的网络结构由两部分组成:图像 Image Encoder + 文字 Text Encoder。
C.核心工作流程
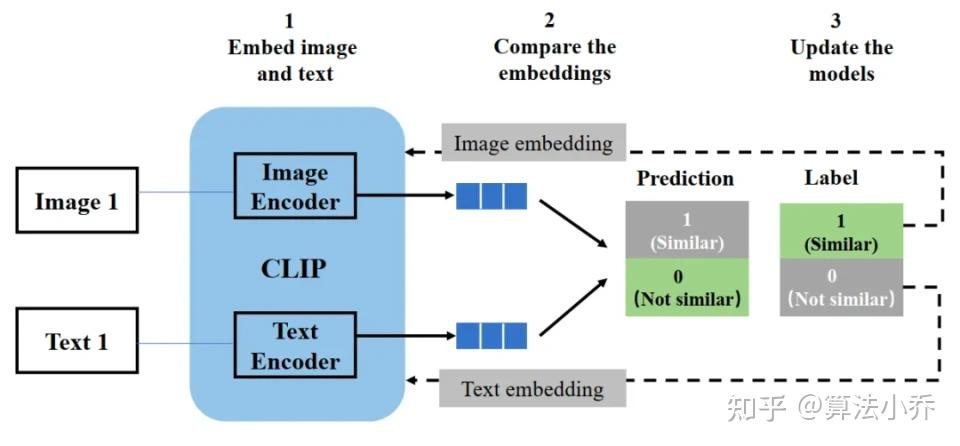
步骤 1:嵌入图像和文本(Embed image and text)
CLIP 模型里有专门的图像编码器(Image Encoder)和文本编码器(Text Encoder)。图像编码器会把输入的图像(如 “Image 1”)转化为图像嵌入向量(Image embedding),文本编码器则将输入的文本(如 “Text 1”)转化为文本嵌入向量(Text embedding),这样就把图像和文本都转化成了机器能处理的向量形式。
步骤 2:比较嵌入向量(Compare the embeddings)
得到图像嵌入向量和文本嵌入向量后,会对它们进行比较,判断两者是否相似。图中 “Prediction” 部分的 “1(Similar)” 表示预测为相似,“0(Not similar)” 表示预测为不相似,同时还有对应的 “Label(标签)”,标签里的 “1(Similar)” 是真实的相似情况,“0(Not similar)” 是真实的不相似情况,通过预测和标签的对比来评估模型判断的准确性。
步骤3:三种 “配对逻辑” 的拆解
我们可以把 “图像 - 文本” 的匹配关系拆成 “图像对文本的匹配” 和 “文本对图像的匹配” 两个视角,从而产生不同的标签组合:
- 「1 - 1」:完美匹配
- 「1 - 0」:图像认为匹配,文本认为不匹配(几乎不存在,因为数据是 “配对提供” 的)
步骤 3:更新模型(Update the models)
根据预测结果和真实标签之间的差异,来调整图像编码器和文本编码器的参数,让模型在之后能更准确地判断图像和文本是否匹配,不断优化模型的性能。
上面讲了Batch为1时的情况,当我们把训练的Batch提高到N时,其实整体的训练流程是不变的。只是现在CLIP模型需要将N个标签文本和N个图片的两两组合预测出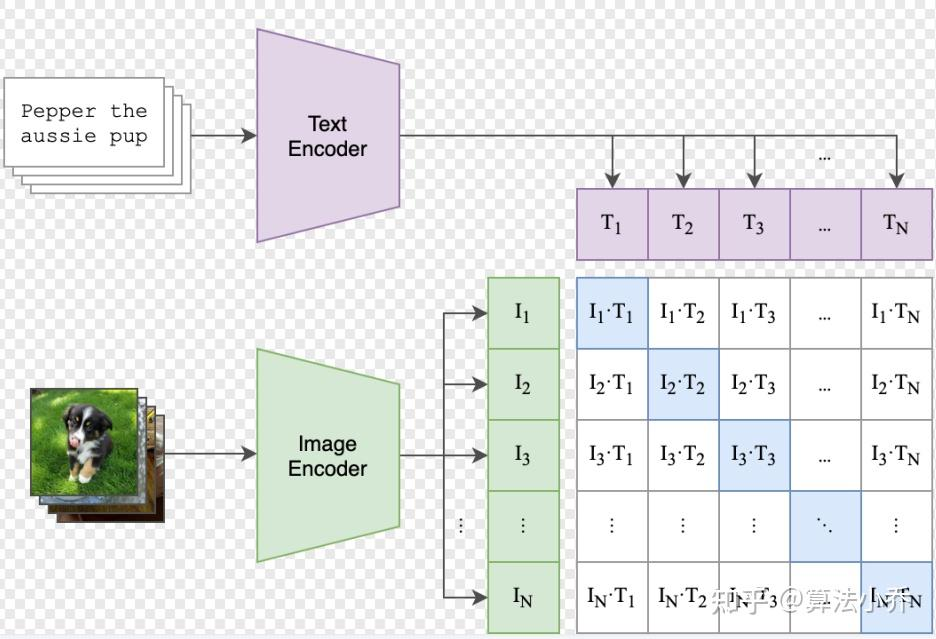
具体计算过程:
一、核心符号定义
- 设一批训练数据包含 N 个图文对:
,其中 为文本, 为对应的图像。 - 文本编码器输出文本特征向量:
(维度为 d 的向量)。 - 图像编码器输出图像特征向量:
(维度同样为 d 的向量)。 - 对所有向量进行
归一化: , (确保向量模长为 1,简化相似度计算)。 扩展: 归一化(也叫 “欧几里得归一化”)的核心是:把向量的 “长度(模长)” 缩放为 1,但保持向量的 “方向” 不变。 是文本编码器输出的原始文本向量, 是 的 范数(即向量的模长,计算方式为 ,d 是向量维度)。 表示:把原始向量 的每个元素,都除以它的模长 ,得到新向量 。 - 对图像向量
的处理 逻辑完全相同。
二、相似度计算
文本与图像的语义相似度通过向量点积计算(归一化后等价于余弦相似度):
三、对比损失函数(InfoNCE Loss)
CLIP 的训练目标是最小化对比损失,让匹配的图文对
1. 单样本损失(对第 i 个图文对)
对于文本
同理,对于图像
其中
2. 批量总损失
对所有 N 个样本的文本和图像视角损失取平均,得到总损失:
代入单样本损失公式后展开:
四、推导逻辑与目标
- 当模型训练理想时,匹配的图文对相似度
应显著大于所有不匹配的 。 - 此时分子
远大于 分母中的其他项,导致 内的值接近 1,损失 L 趋近于 0。 - 反之,若模型无法区分匹配 / 不匹配对,损失会增大,通过反向传播迫使模型调整文本编码器和图像编码器的参数,最终让语义相关的图文对在向量空间中更接近。
在 CLIP 模型完成训练后:
输入配对的图片和文字,两个 encoder 就可以输出相似的 embedding 向量,余弦相似度接近于1;
输入不匹配的图片和文字,两个 encoder 输出向量的余弦相似度就会接近于 0。
D. SD中的应用
上面讲到了CLIP模型的Image Encoder 和 Text Encoder两个模块,在Stable Diffusion中只用到了Text Encoder模块。
CLIP Text Encoder模型将输入的文本Prompt进行编码,转换成Text Embeddings(文本的语义信息),作为UNet网络的Context输入,并在UNet网络中的CrossAttention模块中,结合提取特征F对生成图像的内容进行一定程度的控制与引导;
E. Text Encoder 网络结构
目前SD中用到的是CLIP ViT-L/14中的 Text-Encoder模型,网络结构如下: 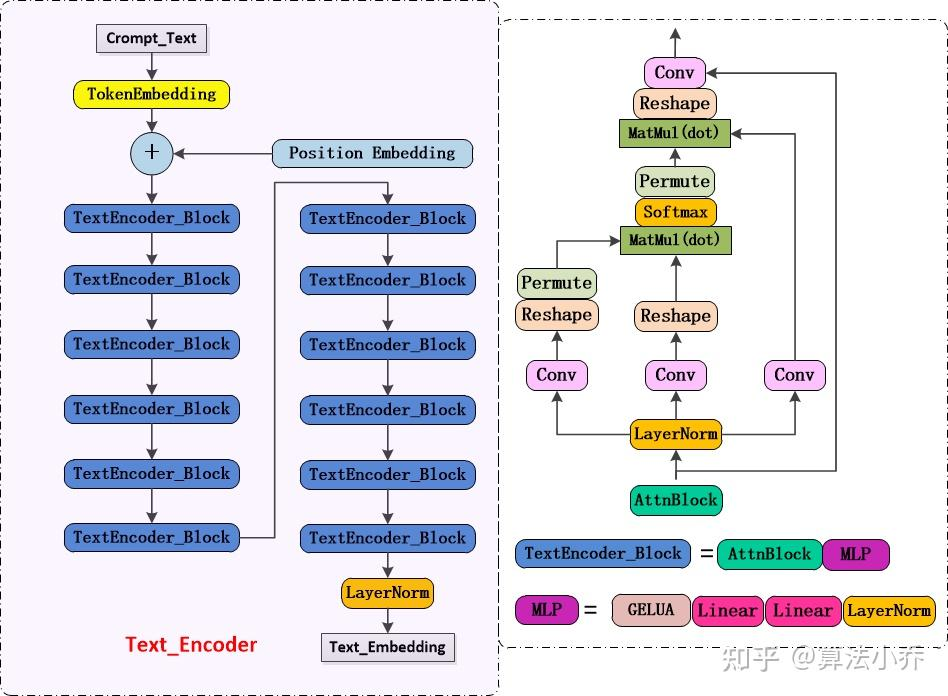
由上图可见,Text Encoder 是由 Transformer 中的 SelfAttention + FeedForward 组成,一共有12个 TextEncoder_Block 模块,模型参数大小为123M,其中特征维度为768,token数量为77,故输出的 Text_Embedding 的维度为77x768。
F. Text Encoder代码
import torch
import torch.nn as nn
from transformers import CLIPTokenizer,CLIPTextModel
class Text_Encoder(nn.Module):
'''
clip-vit-large-patch14为模型参数,需要提前单独下载并保存于本地
'''
def __init__(self,version='/本地路径/clip-vit-large-patch14',device='cuda',max_length=77,freeze=True):
super(Text_Encoder,self).__init__()
# 定义文本的tokenizer和transformer
self.tokenizer = CLIPTokenizer.from_pretrained(version)
self.transformer = CLIPTextModel.from_pretrained(version).to(device)
self.device = device
self.max_length = max_length
# 冻结模型参数
if freeze:
self.freeze()
def freeze(self):
self.transformer = self.transformer.eval()
for param in self.parameters():
param.requires_grad = False
def forward(self,text):
# 对输入图片进行分词并编码,长度不足时直接padding到77
batch_encoding = self.tokenizer(text,truncation=True,max_length=self.max_length,return_length=True,
return_overflowing_tokens=False,padding='max_length',return_tensors='pt')
# 拿出input_ids然后传入transformer进行特征提取
tokens = batch_encoding['input_ids'].to(self.device)
outputs = self.transformer(input_ids=tokens,output_hidden_states=False)
out = outputs.last_hidden_state
return outG. 注意事项
<1> CLIP在训练时设定的最大Token数量为77,故SD在前向推理时:
- 如输入的Prompt的Token数量超过77,则会采取切片操作,只取前77个;
- 如输入Token数量小于77,则采取Padding操作,得到77x768;
<2> 在SD模型训练过程中,CLIP 的Text Encoder的模型参数是冻结Freeze的,无需重新训练; 原因:预训练的CLIP模型已经足以满足后面的任务需求。