推荐李沐老师的课程
PyTorch基础
一、Graph计算图——TensorFlow的计算模型
计算图是TensorFlow中最基本的一个概念,TensorFlow中的所有计算都会被转化为计算图上的节点,依据节点中传递的值,进行数值的“Flow”。
1、计算图的概念
TensorFlow是一个通过计算图的形式来表述计算的编程系统,TensorFlow中的每一个数都是计算图上的一个节点,而节点之间的边描述了节点之间的计算关系。
# 定义tensor常量(constant)
v1 = tf.constant(1,name='v1',shape=(),dtype=tf.float32)
v2 = tf.constant(2,name='v2',shape=(),dtype=tf.float32)
# 定义一个tensor运算
add = v1 + v2
# 创建会话,运行运算,这部分会在之后详细介绍
with tf.Session() as sess:
print(sess.run(add)) #输出:3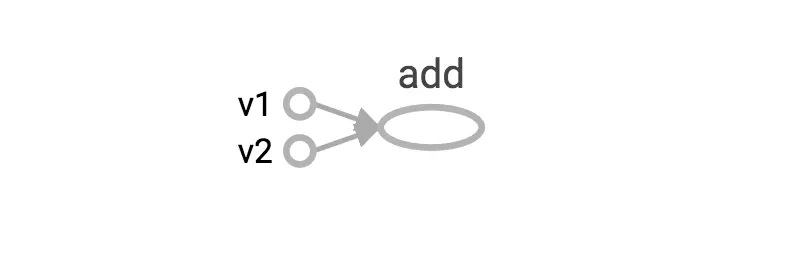
二、Tensor张量的三个属性
tensor具有三个很重要的属性:name、shape和type。
1.name
name是tensor的唯一标识符。
# 定义tensor,第一个参数是值;第二个参数是tensor的name;
#第三个参数是tensor的shape;第四个参数是tensor的type
v1 = tf.constant(1,name='v1',shape=(),dtype=tf.float32)
v2 = tf.constant(2,shape=(),dtype=tf.float32)
# 定义一个tensor运算
add = v1 + v2
print(v1) #Tensor("v1:0", shape=(), dtype=float32)
print(v2) #Tensor("Const:0", shape=(), dtype=float32)还是上面一样的代码,我们将v2常量定义的时候,不去定义它的name属性,然后直接打印v1和v2,我们可以看到当我们不指定name的时候,TensorFlow会自动帮我们定义name属性。
tensor通过node:src_output的形式展示,其中node就是tensor的name,src_output是当前tensor的第几个输出。例如:v1:0就是v1节点的第一个输出(src_output从0开始) 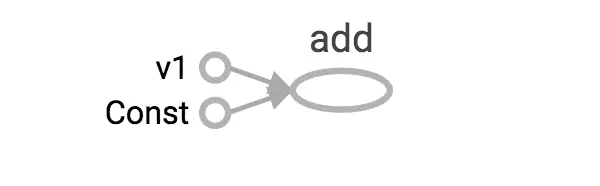
2.shape
shape是纬度,它描述了tensor的纬度信息
# 定义两个二维数组
v1 = tf.constant(1,name='v1',shape=(2,2),dtype=tf.float32)
v2 = tf.constant(2,name='v2',shape=(2,2),dtype=tf.float32)
add = v1 + v2
with tf.Session() as sess:
'''[[1. 1.]
[1. 1.]]'''
print(sess.run(v1))
'''[[2. 2.]
[2. 2.]]'''
print(sess.run(v2))
'''[[3. 3.]
[3. 3.]]'''
print(sess.run(add))上面的这个就是一个二维的张量相加,(eg.shape(2,3)表示一个大数组里面3个小数组,每个小数组里面2个数。)
3.type
每一个tensor会有一个唯一的类型。TensorFlow会对参与计算的所有张量进行类型检测,当类型发生不匹配时会报错。
#TypeError: Input 'v2' of 'Add' Op has type float32
#that does not match type int32 of argument 'v1'
v1 = tf.constant(1,name='v1',shape=(1,2),dtype=tf.int32)
v2 = tf.constant(2,name='v2',shape=(2,1),dtype=tf.float32)
add = v1 + v2等等参考
三、OP节点
上图所示每个椭圆要素代表着计算图中的节点操作(又称 OP),节点在 TensorFlow 中以张量的形式表现出来,而每个节点之间连接线代表着节点之间的流动关系。
四、Session会议
TensorFlow中的会话用于执行定义好的运算。会话拥有并管理 TensorFlow程序运 行时的所有资源。所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄漏的问题。
简单的理解TensorFlow在定义好变量和计算的时候,并不会马上进行计算,需要通过session来进行执行,这就好比我们搭电路图,当电路连接完,当插头通电的时候,整个电路才开始运作。
# 定义tensor
v1 = tf.constant(value=1,name='v1',shape=(1,2),dtype=tf.float32)
v2 = tf.constant(value=2,name='v1',shape=(1,2),dtype=tf.float32)
# 定义计算
add = v1 + v2
# 创建session
sess = tf.Session()
# 执行计算
result = sess.run(add)
print(reslut)
# 关闭session,避免资源泄漏
sess.close()
# 输出结果:[[3. 3.]]使用这种方式调用session需要明确调用Session.close()来关闭session并释放资源避免资源泄漏问题。
当然,我们更多用到的是通过Python的上下文管理器来使用session,来自动释放所有资源。
# 定义tensor
v1 = tf.constant(value=1,name='v1',shape=(1,2),dtype=tf.float32)
v2 = tf.constant(value=2,name='v1',shape=(1,2),dtype=tf.float32)
# 定义计算
add = v1 + v2
# 创建session
with tf.Session() as sess:
# 执行计算
sess.run(add)这样我们就可以不用手动的调用Session.close()来关闭会话了。
五、copy和clone的区别
浅拷贝:
如切片 new_tensor = tensor[:] tensor.view() 是视图,新张量与原张量共享存储,修改会相互影响,且无梯度关联;只是一个view
x = torch.tensor([1.0, 2.0])
# 切片拷贝是浅拷贝,共享内存
y = x[:]
y[0] = 100 # 修改 y,x 也会变
print(x) # 输出 tensor([100., 2.])
print(y) # 输出 tensor([100., 2.])深拷贝,clone是Tensor 内置方法):
x = torch.tensor([1.0, 2.0], requires_grad=True)
# 手动组合:detach() 脱离计算图 + clone() 深拷贝
y = x.detach().clone()
y[0] = 100 # 修改 y,x 不变
print(x) # 输出 tensor([1., 2.], requires_grad=True)
print(y) # 输出 tensor([100., 2.])(无 requires_grad)
# 反向传播:y 脱离计算图,不影响 x
z = x ** 2
z.backward() #因为反向传播相当于是再次计算了一遍完整的过程,所以设置了了这个函数控制是否反向传播,来计算x的偏导也就是属性grad的值
print(x.grad) # 输出 tensor([2., 4.])
print(y.grad) # 输出 None(无梯度追踪)六、偏导
x.grad #给向量x加上一个属性
#...
#但是在次应用的时候,这个数会累加(+),所以需要清零
x.grad.zero_()
y = x * x
u = y.detach #意思是把这个y当做常数,而不是只想计算图的指针
z = u * x
#对于z求导,结果是u,因为u是一个常数结果是x * x的常数七、loss会计算成标量的原因
1,无法评判大小
在 y = x * x 的时候计算出来一个
如果不用L2,则loss是向量 [
2,计算量大
在反向传播计算更好的 w* 的时候,这里也要用到对loss求w的骗到如果是向量的
八、随机打乱list里的值
num_len = len(featurn)#这个特征值的个数
indices = list(range(num_len))
random.shuffle(indices)九、分批训练
def data_iter(batch_size,featurn,lable):
for i in range(0,num_examples,batch_size)
batch-indices = torch.tensor(indeices[i:min(i + batch_size
,num_example)])
yield feature[batch_indices],lable[batch_indices]